 400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
2026年1月7日 • 作者:DataPipeline



一、项目背景与目标
某全国性股份制商业银行近年来保持稳健发展,在夯实客户基础、完善战略客群体系的同时,持续加大科技投入,系统推进数字化与数智化转型。在监管趋严、风控与合规压力上升,金融科技在风险识别、精准管控及降本增效中的作用日益凸显的背景下,该行进一步加码科技建设,推动业务发展由合作依赖向自主可控转变。近五年来,其科技投入占营收比例整体高于上市银行约 4.5% 的平均水平,并稳定处于头部股份制银行 4.8%–5.5% 的核心区间。
随着业务规模和实时化需求持续提升,原有系统架构在数据时效性和系统协同方面逐步显现瓶颈。为支撑新一代核心系统建设,该银行基于国产数据库推进系统升级,并同步建设实时数据融合平台,强化多源数据的实时流转与统一支撑能力。
1. 技术目标
· 构建统一的实时数据融合平台,实现多源异构系统数据的实时采集、同步与分发,支撑核心系统与关键业务场景稳定运行。
· 在复杂系统架构和不停机升级条件下,保障数据同步任务持续可用与数据一致性,满足高可靠、高兼容的技术要求。
2. 业务目标
· 支撑关键业务指标与流程数据的实时获取与可视化,提升经营监控和管理决策的时效性与准确性。
· 以实时数据能力为基础,提升业务系统协同效率,推动核心业务场景的数智化升级与精细化运营。
二、为什么选择DataPipeline
围绕实时化、稳定性和系统复杂度并存的建设目标,该银行需要一款在性能、可靠性与工程可落地性上均经得起验证的实时数据融合产品。DataPipeline 企业级实时数据融合平台在多源异构数据实时同步、任务稳定运行和复杂架构适配方面具备成熟能力,能够在不停机升级和多版本组件并行的条件下,持续保障数据一致与链路可控。同时,平台通过标准化能力封装与直观可用的配置方式,显著降低了系统集成与运维复杂度,使实时数据能力可以更快、更稳地服务于核心业务与管理场景。
三、实施方案
在新一代核心系统升级与实时数据能力建设过程中,DataPipeline 为该银行提供了一套可在复杂技术环境下稳定运行的实时数据融合实施方案。平台全面适配 OceanBase、阿里云 DRDS、阿里云 RDS、达梦、openGauss、ArgoDB、Inceptor 等多种数据库管理技术,为异构数据的实时传输与处理提供了统一、可靠的技术支撑。目前,相关能力已成功接入业务营运实时监控大屏,并在生产环境中以并行方式运行验证,整体表现稳定,满足行内对实时性与安全性的双重要求。
在数据链路设计上,平台对上游核心系统、业务运营、信贷、理财等系统进行统一接入与管理,对实时数据进行标准化处理后,下发至实时大屏、数据采集交换体系及零售客户等下游应用,形成结构清晰、职责明确的实时数据流转体系。
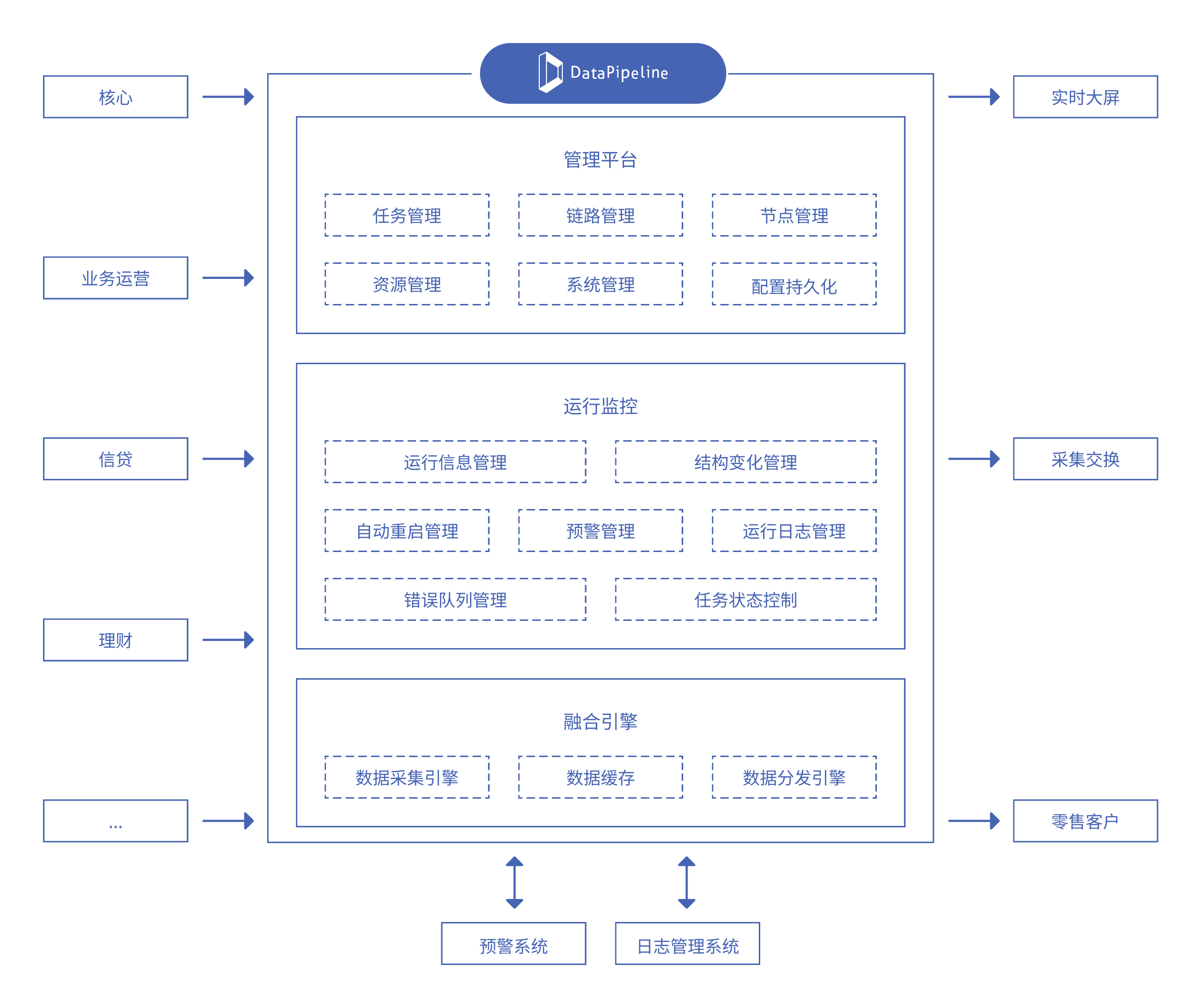
实时数据融合平台架构
在具体实施过程中,DataPipeline 提供了以下关键能力支撑:
▶ 极致的性能优化:通过可选的内存模式与链路优化,实现数据不落地的高性能实时同步,有效满足关键业务场景的低延迟需求;
▶ 全面的数据节点支持:支持多类型数据节点的统一接入与实时分发,保障数据在不同系统与应用间的实时可用性与一致性;
▶ 简化的配置流程:以配置化方式完成数据采集与加工,降低系统集成和二次开发成本;
▶ 灵活的资源管理:结合自动化运维体系,实现资源的灵活调度与扩缩容,确保系统在高并发和复杂运行环境下持续稳定。
通过该实施方案,该银行在核心业务与管理场景中逐步构建起稳定、可持续演进的实时数据支撑体系,为后续数智化应用落地提供了可靠的数据基础。
四、实施成果
目前,DataPipeline 实时数据融合平台已上线稳定运行8个月,显著提升该银行在实时数据处理与业务支撑层面的整体能力。平台已覆盖行内 40 余个业务场景,在数据同步效率、处理规模和运行稳定性方面均达到较高水准:数据同步延时稳定控制在 6 秒以内,每日新增数据量约 6000 万条,同时支撑 亿级历史全量数据 的持续管理与实时联动,充分验证了平台在生产环境下的高性能与高可靠性。
1. 技术成果
· 在高并发、复杂系统环境下,实时数据链路长期稳定运行,低延迟同步能力在核心与关键业务场景中得到持续验证,技术指标与既定技术目标保持一致。
· 面对大规模数据增量与存量并存的运行状态,平台在性能、稳定性和可扩展性方面表现稳定,为后续系统演进和实时能力扩展预留了充足空间。
2. 业务成果
· 实时数据能力已深度支撑多类业务场景运行,为业务监控、运营分析和管理决策提供了更及时、可信的数据基础。
· 通过统一的数据融合与分发体系,业务系统间的数据协同效率显著提升,减少了数据时延对业务流程的影响,为银行数智化应用的持续落地提供了有力支撑。





