
 400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO

宁波太平鸟时尚服饰股份有限公司是一家以顾客为中心的时尚品牌零售公司,拥有遍布全国 31 个省市自治区的 4500 余家实体门店。其中太平鸟电商事业部,负责太平鸟服饰所有电商业务。 疫情期间,太平鸟电商的稳健增长很大程度上弥补了线下门店无法正常营业带来的经济损失。数字背后,是太平鸟电商践行"聚焦时尚、数据驱动、全网零售"战略的结果。

集成商开发的采集程序是通过批量抽取的方式同步数据,抽取频率过高会严重影响业务库的性能,甚至导致锁表。
批量抽取要求表有增量识别字段,且要保证增量字段在数据发生变更时能更新,否则无法同步增量数据。另外批量方式不支持删除操作,会导致源端和目的地数据量不一致。
业务系统由于需求变更,版本更新时可能会修改表结构,比如增加新字段,现有采集程序无法自动捕获DDL变更,自动修改数据目的地表结构,会出现源端和目的地表结构不一致等情况。
DataPipeline的agent技术可支持解析Oracle RAC集群的redo以及archive log,通过流式处理框架,实现秒级延迟。该方式无需批量查询数据库,对数据源的资源占用很少,最大程度减少对业务库的影响。
DataPipeline可解析日志中的DML操作语句,支持insert update及delete操作,此外产品从框架层面支持“At Least Once“,保障端到端的一致性。
DataPipeline 能自适应表结构变化,通过任务配置相应策略,即可实现表结构变化的自动同步,当出现字段增删的情况时,无需人工干预即可完成表结构自动同步。
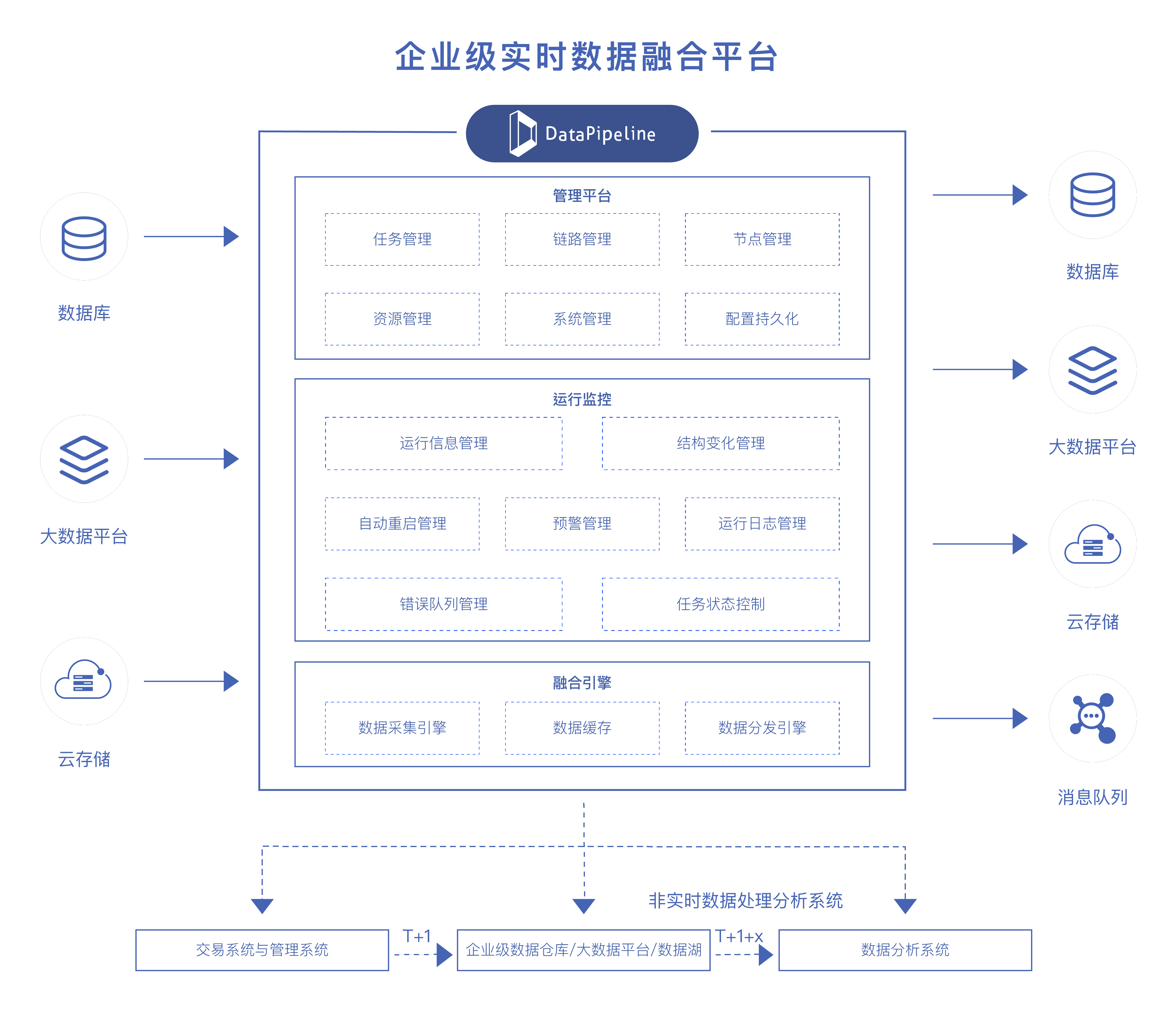

在不影响业务库性能的前提下,实现了高性能低延迟的实时数据同步功能,且能保证数据一致性,满足了数据团队的用数需求。

简单友好的操作界面,可快速搭建数据同步管道,并且自适应表结构变化,极大减轻了运维压力,提高了团队的工作效率。

除关系型数据库外还支持多种数据源,如FTP、API等,帮助客户快速接入如阿里妈妈的营销数据等更多的平台数据,迅速提升数据服务器能力。

